在整理车站数据过程中,做了很多的搜索,又产生了一些AHA,各大网站搜索优化的方式,更多是针对某些特定问题,利用自身数据,设计模板,批量创建网页。

首先看看Google搜索”london train station to stroke Newington”的结果
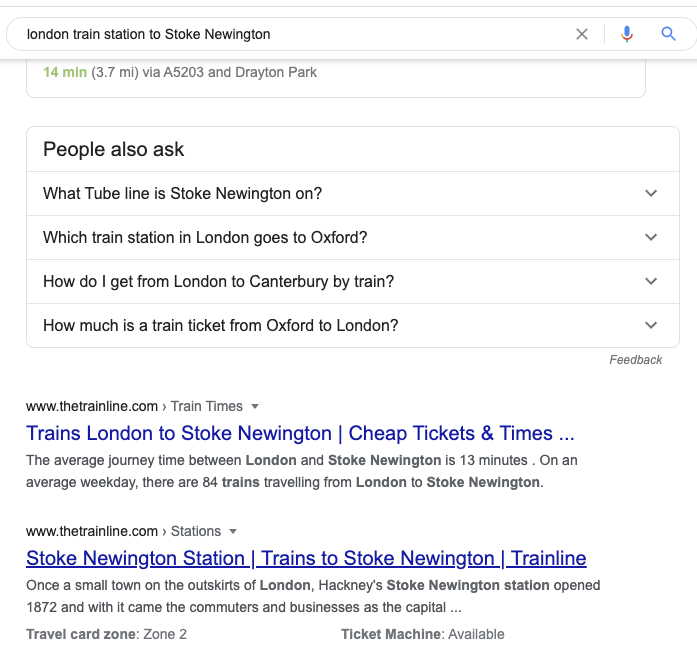
搜索英国的小车站火车站(因为大车站大家都会有文章,竞争比较激烈),所以很多结果其实是Trainline的,一般会展示两种页面:
- Trains London to Stroke Newington
- Stoke Newington Station | Train to Stoke Newington
在这里其实可以看出Trainline在SEO时关注于回答两个问题
- 关于数据库中热门路线,从A到B如何走?
- 关于数据库中某个点,比如车站,如何到达某个车站。
搜索”London train to Abbey Wood”其实也是类似的结果。
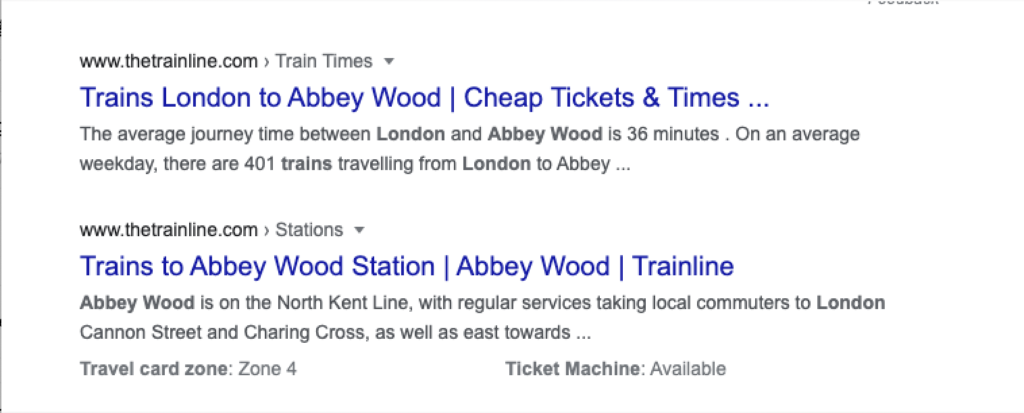
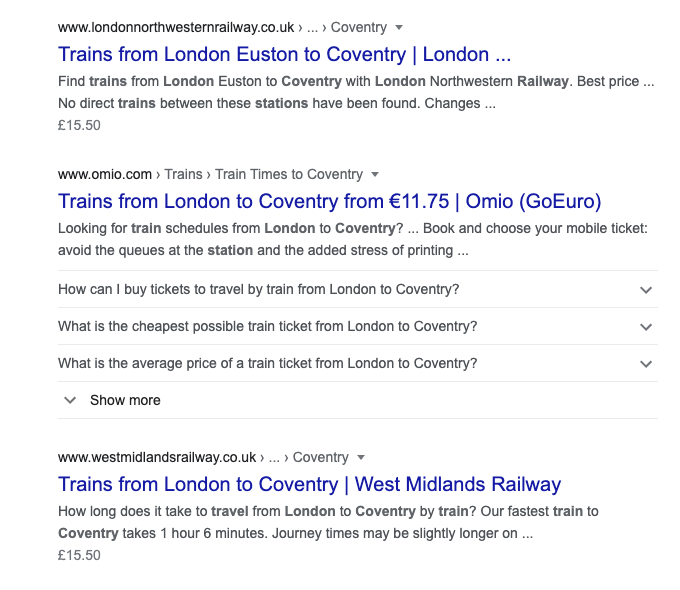
因此这些网页其实是根据数据库中数据然后根据模板生成的。搜索也会出现Omio的结果和一些铁路公司的结果。可以看出Omio和一些铁路公司更多的是按照路线来生成网页,比如下图的伦敦尤思顿车站到考文垂。
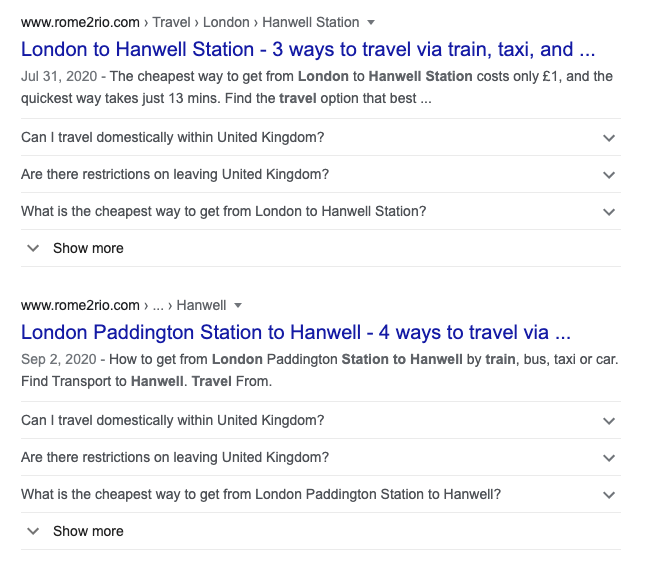
Roma2Rio的网页生成会更加细致一些,因为不光产生了城市之间的,而且产生了城市中某个位置之间的信息。不光有London to Hanwell,还有伦敦帕丁顿车站到Hanwell。而背后是因为数据支撑,才能够产生出这样的有意义的路线页面。
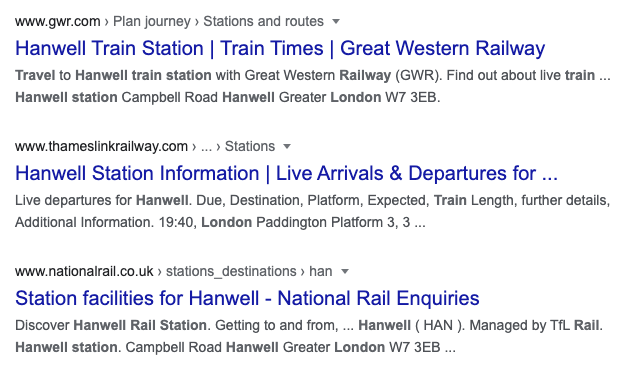
铁路公司试图回答的问题与上面不尽相同。两家铁路公司Great Western Railway和Thameslink Railway,以及国家铁路联盟National Rail尝试回答的问题更多是
车站有哪些设施,列车的晚点情况。
而Moovit的目标更多是以目的地为中心的,尝试回答的问题是
如何到达那个地方。

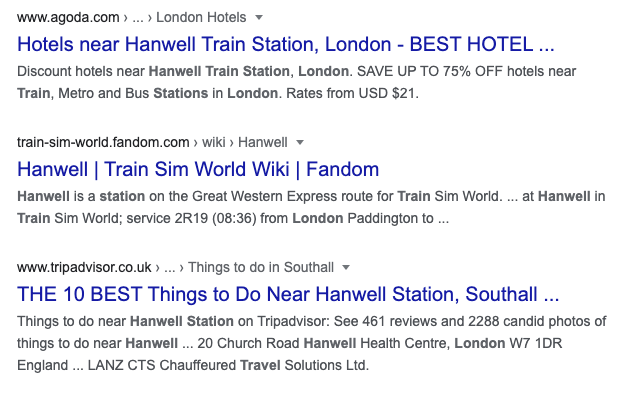
Agoda和TripAdvisor的产品更多酒店以及吃喝娱乐的,所以搜索结果更多展示某个地点周围的相关信息。他们的问题模板是
在某个地方附近有哪些好吃的、能住的、好玩的
这其实提醒了《必然》里面的第十一个趋势Questioning。
Answers become cheap and question become valuable
而核心能力是
- 如何发现问题
- 如何获取利用数据形成无数的相关、详尽的答案
