
最近几个月一直在做的一件事情是把G2Rail的数据语义化,而这件事情对于G2Rail下一步的演化会产生长远的影响。
早期的G2Rail已经演化出了一些铁路领域的概念,比如TicketTariff, CoachClass, Carrier, Train, Service Provider等等。比如一个旅客查询火车票,他需要看到。

早期版本的G2Rail的退改签条款以及舱位设施的数据完全是人肉整理,然后利用Markdown格式存放在数据库里。最初支持的铁路公司数量有限,火车种类和票种也是有限,利用人肉维护还ok。
但是随着系统的不断演化,同时随着与愈来愈多的像阿里这样大玩家对接,大玩家也会给我压力,对于G2Rail数据一致性,数据完整性的要求也越来越高。我们的这些领域概念以及相应的数据已经跟不上这种要求。我们的解决方案是把这些数据语义化。
所谓语义化是指,最初的“不能退票”这只是TicketTariff的一个文本描述,我们系统并不能把这一段描述与我们系统里这个票种(TicketTariff)意味着不能退票这个业务行为联系起来。我们需要让我们的系统学会理解这些文本背后的业务意义。因此对于TicketTariff来说,比如需要知道是否可以退改、是纸质票还是电子票、是否包含座位。对于CoachClass来说,需要知道是否有Wifi,是否有食品,是否有插座等等。
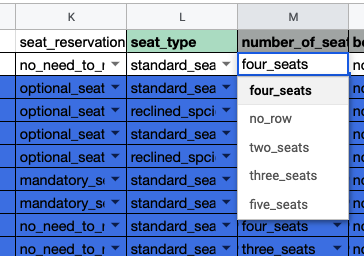
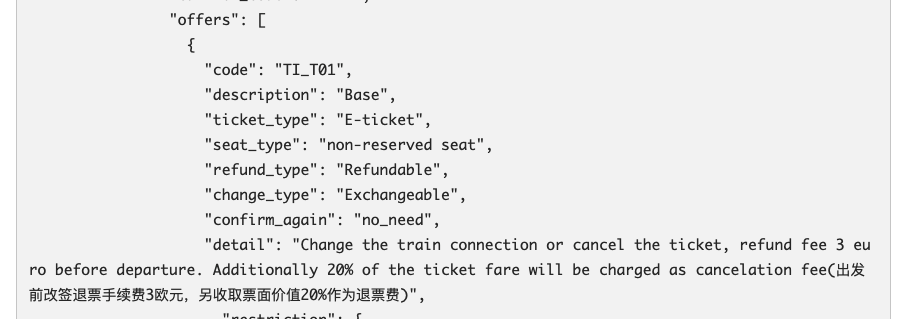
通过语义化,把原先粗粒度的领域概念,赋予了更多、更细微的领域意义(而不是文本)。这一切给G2Rail带来了很多直接好处:
- 数据的完整性和一致性更容易保证
- 可以通过利用语义生成相应的描述文本
- 根据语义生成多语言版本也变得无数简单,而且短句子翻译也提高了翻译准确度。
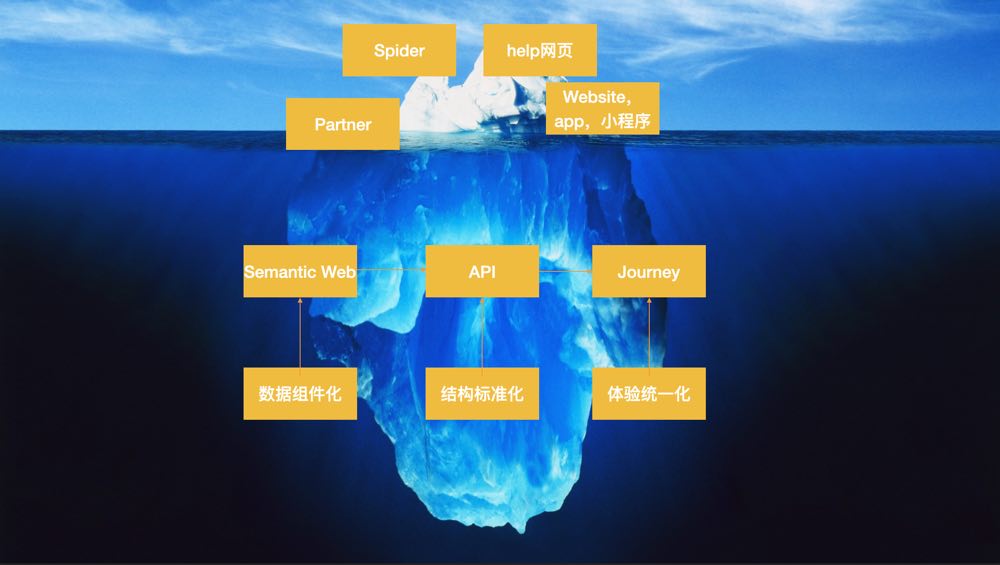
更长远的好处是,通过这些语义字段,组成了一个基于地面交通语义网络。G2Rail根据这个语义网络生成了关于全球地面交通的Wikipedia,可以查询到各国各种车型、各种票种、各个车站的众多信息。这对于G2Rail的搜索引擎优化有很大意义。而有了这个语义网络作为基础,G2Rail可以极快的迭代我们的产品的乐高积木。
